Since machine learning methods were largely out of the question due to the project parameters, we opted to use a rules-based approach optimized for Wikipedia to understand and generate English sentences.
I came up with our core strategy of representing all sentences in a predicate-argument structure based on literature research and familiarity with first order logic. With dependency parsing, we could isolate parts of speech and conduct named entity recognition and coreference resolution to identify predicates and arguments.

An example of how our system converts sentences into a representation of the sentence.
I researched tools that could help us fulfill our goal of representing all sentences in predicate-argument form. Ultimately, we settled on a tool called Graphene created by researchers at the University of Passau in Germany. Graphene provided the exact tools we need to help us accomplish our task: parsing, coreference resolution, and sentence simplification. It even output simplified sentences in predicate-argument format!
This was one of my first experiences working with open-source code shared on GitHub, and it came with its own share of issues. I learned about Docker containers, memory issues in compute-intensive NLP programs, legacy version management of Java/Python, building REST APIs into our system, and bug reporting on GitHub. All-in-all, getting Graphene to work required almost two weeks.
With Graphene successfully outputting to our system, we began integrating it with components of our pipeline such as information retrieval, ranking, and pruning. Graphene provided the internal representation, but we still needed to be able to output human-readable text. This is where our custom rules for forming sentences came into play. You can see what our overall pipeline looks like below and which tools we use.
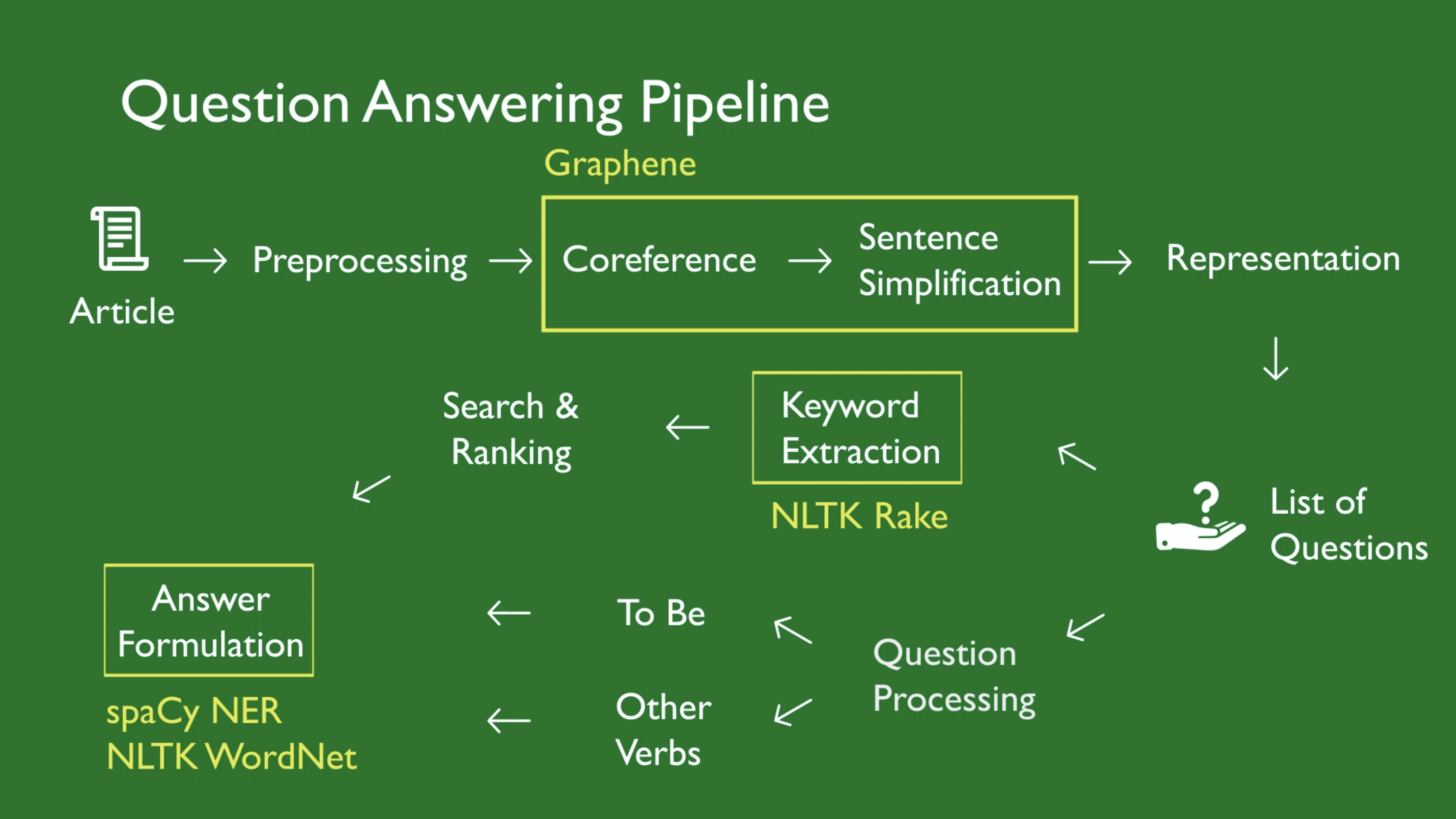
In total we use four different external tools to get the job done. Note that our list of questions is provided as a second input into the system.
For QA, I contributed to the design of our question processing step by formulating different paths for yes/no questions and other types of questions. Yes/no questions are often formed with the verb 'be' and can be answered by inverting the verb and the subject of the sentence. Other questions, such as those starting with "who", "what", "when", "where", or "why", were more complex create.
I also coded part of our answer formulation using WordNet to leverage word senses for disambiguation. Our system had no way of knowing if the answer it found to a question was nonsense or not. For example, when given the question "How long did Tony go to school?", our system should be able to output an answer about time like "Tony went to school for a year." instead of "Tony went to school for himself." even if the underlying logical structures are similar.
Our QG pipeline reuses significant parts of our entire pipeline, but features some key differences to make sure that the sentences our system outputs are as natural and concise as possible.
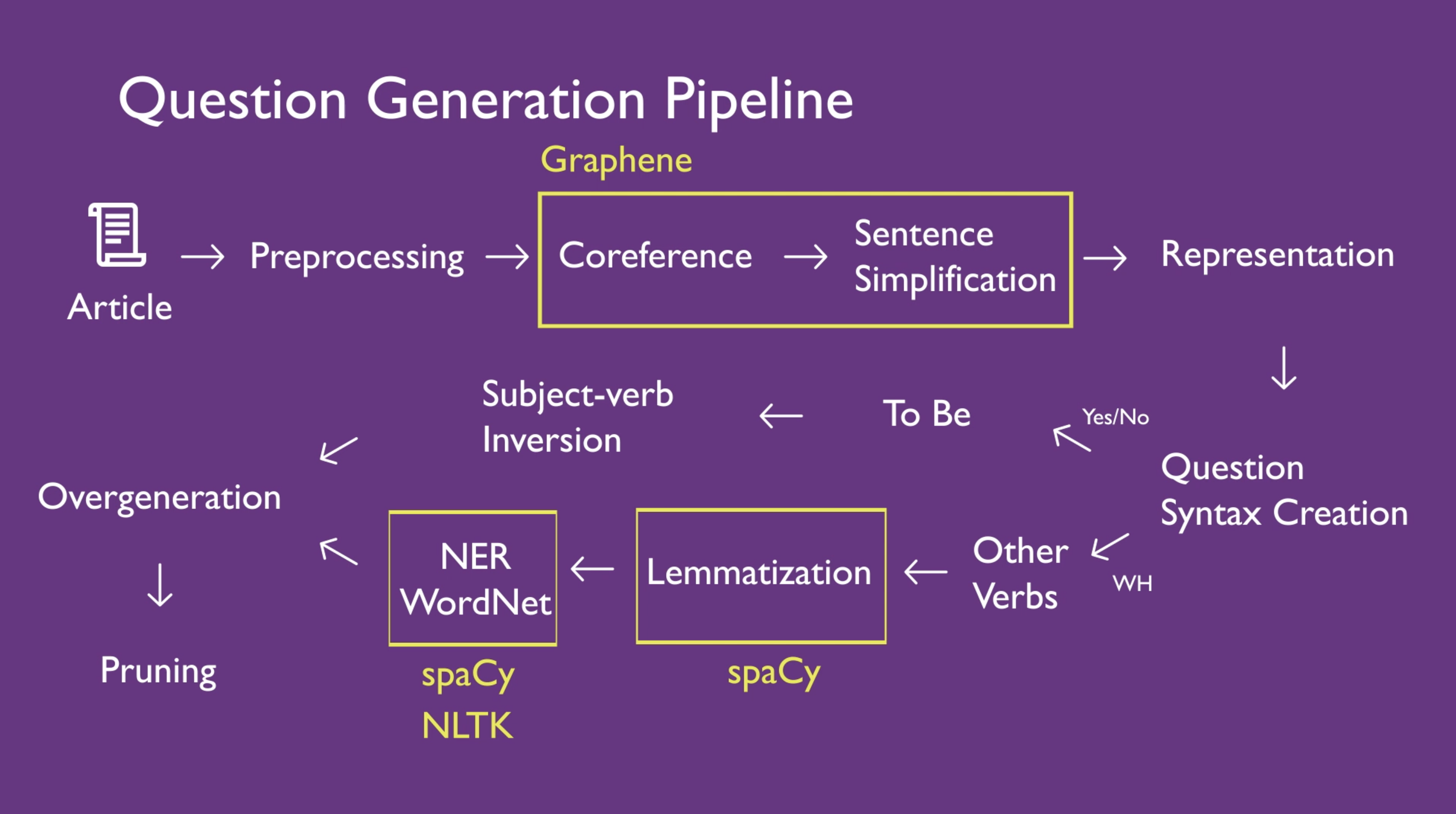
In order to prevent our system from generating nonsense sentences, we have two additional steps at the end of our QG pipeline.
One key aspect of the QG system that I worked on is the pruning mechanism. Jambalaya will take sentences in a Wikipedia article and create questions from that content based on the predicate-argument structure found in our system. For example, our system can interpret structure gave(John, the ball, to Jim) as "What gave the ball to Jim?" because it's unaware that John is a person.
I opted to leverage deeper syntax processing methods by training a Hidden Markov Model and using it as a mechanism for finding the most probable interrogative sentences. The system first generates every single possible sentence from the underlying predictate-argument form and then keeps only the most likely questions. This way, it would be unlikely for us to output nonsense questions like "John gave the ball to where?".
To accomplish this, I extracted questions from the Stanford Question Answer Dataset, applied a part-of-speech tagger to the questions, and fed tag and emission information as training data into an HMM algorithm that all students in the class had access to. The result was a working model that could prune our overgenerated sentences and allow us to only output what would be our most natural questions.